Das dritte Normalform (Datenbanken) ist eine relationale Datenbankentwurfstechnik, bei der die verschiedenen Tabellen, aus denen sie besteht, nicht nur der zweiten Normalform entsprechen, sondern alle ihre Attribute oder Felder direkt vom Primärschlüssel abhängen.
Beim Entwerfen einer Datenbank besteht das Hauptziel darin, eine genaue Darstellung der Daten, der Beziehungen zwischen ihnen und der relevanten Datenbeschränkungen zu erstellen..
Um dieses Ziel zu erreichen, können einige Datenbankentwurfstechniken verwendet werden, darunter die Normalisierung.
Hierbei handelt es sich um einen Prozess zum Organisieren der Daten in einer Datenbank, um Redundanzen und mögliche Anomalien beim Einfügen, Aktualisieren oder Eliminieren der Daten zu vermeiden und ein einfaches und stabiles Design des konzeptionellen Modells zu erstellen..
Zunächst wird die funktionale Beziehung oder Abhängigkeit zwischen Attributen untersucht. Diese beschreiben einige Eigenschaften der Daten oder die Beziehung zwischen ihnen.
Artikelverzeichnis
Bei der Normalisierung werden eine Reihe von Tests verwendet, die als Normalformen bezeichnet werden, um die optimale Gruppierung dieser Attribute zu ermitteln und letztendlich die entsprechenden Beziehungen herzustellen, die die Datenanforderungen eines Unternehmens unterstützen.
Das heißt, die Normalisierungstechnik basiert auf dem Konzept der Normalform, das ein System von Einschränkungen definiert. Wenn eine Beziehung die Bedingungen einer bestimmten Normalform erfüllt, wird die Beziehung als diese Normalform bezeichnet.
Eine Tabelle wird als 1FN bezeichnet, wenn alle darin enthaltenen Attribute oder Felder nur eindeutige Werte enthalten. Das heißt, jeder Wert für jedes Attribut muss unteilbar sein.
Per Definition wird eine relationale Datenbank immer auf die erste Normalform normalisiert, da Attributwerte immer atomar sind. Alle Beziehungen in einer Datenbank sind in 1FN.
Das einfache Verlassen der Datenbank führt jedoch zu einer Reihe von Problemen, wie Redundanz und möglichen Upgrade-Fehlern. Höhere Normalformen wurden entwickelt, um diese Probleme zu beheben..
Es geht darum, zirkuläre Abhängigkeiten aus einer Tabelle zu entfernen. Eine Beziehung wird als in 2FN bezeichnet, wenn sie sich in 1FN befindet, und auch jedes Nichtschlüsselfeld oder -attribut hängt vollständig vom Primärschlüssel ab oder stellt insbesondere sicher, dass die Tabelle einen einzigen Zweck hat.
Ein Nichtschlüsselattribut ist ein Attribut, das nicht Teil des Primärschlüssels für eine Beziehung ist.
Es befasst sich mit dem Entfernen von transitiven Abhängigkeiten aus einer Tabelle. Entfernen Sie also die Nichtschlüsselattribute, die nicht vom Primärschlüssel, sondern von einem anderen Attribut abhängen.
Eine transitive Abhängigkeit ist eine Art funktionaler Abhängigkeit, bei der der Wert eines Nichtschlüsselattributs oder -felds durch den Wert eines anderen Felds bestimmt wird, das ebenfalls kein Schlüssel ist..
Suchen Sie nach wiederholten Werten in Nichtschlüsselattributen, um sicherzustellen, dass diese Nichtschlüsselattribute von nichts anderem als dem Primärschlüssel abhängen.
Attribute gelten als voneinander unabhängig, wenn keines von ihnen funktional von einer Kombination anderer abhängig ist. Diese gegenseitige Unabhängigkeit stellt sicher, dass Attribute einzeln aktualisiert werden können, ohne dass die Gefahr besteht, dass ein anderes Attribut beeinflusst wird..
Damit eine Datenbankbeziehung in der dritten Normalform vorliegt, muss sie Folgendes erfüllen:
- Alle Anforderungen von 2FN.
- Wenn es Attribute gibt, die sich nicht auf den Primärschlüssel beziehen, müssen sie entfernt und in einer separaten Tabelle abgelegt werden, die beide Tabellen mithilfe eines Fremdschlüssels verknüpft. Das heißt, es sollte keine transitiven Abhängigkeiten geben.
Die Tabelle sei STUDENT, dessen Primärschlüssel die Identifikation des Schülers (STUDENT_ID) ist und aus den folgenden Attributen besteht: STUDENT_NAME, STREET, CITY und POST_CODE, die die Bedingungen für 2FN erfüllen.
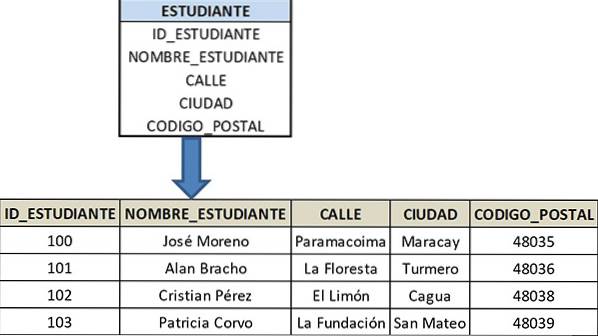
In diesem Fall haben STREET und CITY keine direkte Beziehung zum Primärschlüssel STUDENT_ID, da sie nicht direkt mit dem Schüler verbunden sind, sondern vollständig von der Postleitzahl abhängen.
Da sich der Schüler an der von CODE_POSTAL festgelegten Site befindet, sind STREET und CITY mit diesem Attribut verbunden. Aufgrund dieses zweiten Abhängigkeitsgrades ist es nicht erforderlich, diese Attribute in der STUDENT-Tabelle zu speichern.
Angenommen, es befinden sich mehrere Schüler in derselben Postleitzahl, wobei die STUDENT-Tabelle eine immense Anzahl von Datensätzen enthält und der Name der Straße oder Stadt geändert werden muss. Dann muss diese Straße oder Stadt in der gefunden und aktualisiert werden ganze Tabelle. STUDENT.
Wenn Sie beispielsweise die Straße "El Limón" in "El Limón II" ändern müssen, müssen Sie in der gesamten STUDENT-Tabelle nach "El Limón" suchen und diese dann auf "El Limón II" aktualisieren..
Das Durchsuchen einer großen Tabelle und das Aktualisieren einzelner oder mehrerer Datensätze dauert lange und beeinträchtigt somit die Leistung der Datenbank.
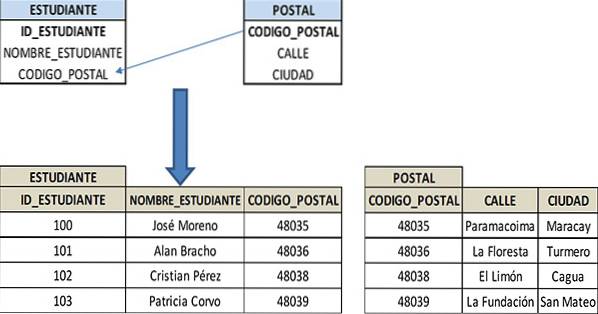
Stattdessen können diese Details mithilfe des POST_CODE-Attributs in einer separaten Tabelle (POSTCARD) gespeichert werden, die sich auf die STUDENT-Tabelle bezieht.
Die POST-Tabelle enthält vergleichsweise weniger Datensätze, und diese POST-Tabelle muss nur einmal aktualisiert werden. Dies wird automatisch in der STUDENT-Tabelle angezeigt, wodurch die Datenbank und die Abfragen vereinfacht werden. Die Tabellen werden also in 3FN sein:
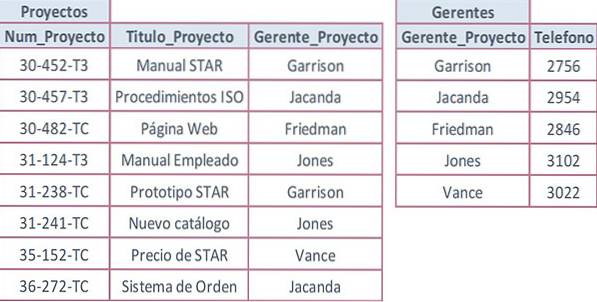
Die folgende Tabelle soll mit dem Feld Project_Num als Primärschlüssel und mit wiederholten Werten in Attributen verwendet werden, die keine Schlüssel sind.
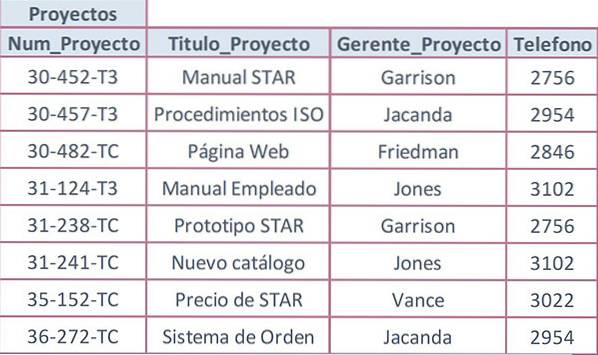
Der Telefonwert wird jedes Mal wiederholt, wenn der Name eines Managers wiederholt wird. Dies liegt daran, dass die Telefonnummer nur eine Abhängigkeit zweiten Grades von der Projektnummer aufweist. Es hängt wirklich zuerst vom Manager ab, und dies hängt wiederum von der Projektnummer ab, die eine transitive Abhängigkeit darstellt.
Das Project_Manager-Attribut kann kein möglicher Schlüssel in der Projects-Tabelle sein, da derselbe Manager mehr als ein Projekt verwaltet. Die Lösung hierfür besteht darin, das Attribut mit den wiederholten Daten (Telefon) zu entfernen und eine separate Tabelle zu erstellen.
Die entsprechenden Attribute müssen zusammen gruppiert werden, um eine neue Tabelle zum Speichern zu erstellen. Die Daten werden eingegeben und es wird überprüft, ob die wiederholten Werte nicht Teil des Primärschlüssels sind. Für jede Tabelle wird ein Primärschlüssel festgelegt und bei Bedarf werden Fremdschlüssel hinzugefügt.
Um der dritten Normalform zu entsprechen, wird eine neue Tabelle (Manager) erstellt, um das Problem zu lösen. Beide Tabellen sind über das Feld Project_Manager verknüpft:

Bisher hat noch niemand einen Kommentar zu diesem Artikel abgegeben.