Das Klassennote, Auch als Mittelpunkt bezeichnet, ist es der Wert in der Mitte einer Klasse, der alle Werte in dieser Kategorie darstellt. Grundsätzlich wird die Klassenmarke verwendet, um bestimmte Parameter wie das arithmetische Mittel oder die Standardabweichung zu berechnen..
Die Klassenmarke ist also der Mittelpunkt eines Intervalls. Dieser Wert ist auch sehr nützlich, um die Varianz eines Datensatzes zu ermitteln, der bereits in Klassen gruppiert ist. Auf diese Weise können wir nachvollziehen, wie weit diese spezifischen Daten vom Zentrum entfernt sind.

Artikelverzeichnis
Um zu verstehen, was eine Klassenmarke ist, ist das Konzept der Häufigkeitsverteilung erforderlich. Bei einem gegebenen Datensatz ist eine Häufigkeitsverteilung eine Tabelle, die die Daten in eine Reihe von Kategorien unterteilt, die als Klassen bezeichnet werden..
Diese Tabelle zeigt die Anzahl der Elemente, die zu jeder Klasse gehören. Letzteres ist als Frequenz bekannt.
In dieser Tabelle wird ein Teil der Informationen, die wir aus den Daten erhalten, geopfert, da wir nicht den individuellen Wert jedes Elements haben, sondern nur wissen, dass es zu dieser Klasse gehört.
Andererseits erhalten wir ein besseres Verständnis des Datensatzes, da es auf diese Weise einfacher ist, etablierte Muster zu erkennen, was die Manipulation dieser Daten erleichtert..
Um eine Häufigkeitsverteilung zu erstellen, müssen wir zuerst die Anzahl der Klassen bestimmen, die wir belegen möchten, und deren Klassengrenzen auswählen..
Die Auswahl der Anzahl der Klassen sollte bequem sein, da eine kleine Anzahl von Klassen Informationen über die Daten, die wir untersuchen möchten, verbergen kann und eine sehr große Klasse zu viele Details generieren kann, die nicht unbedingt nützlich sind.
Die Faktoren, die wir bei der Auswahl der Anzahl der zu berücksichtigenden Klassen berücksichtigen müssen, sind mehrere, aber unter diesen beiden fallen auf: Die erste besteht darin, zu berücksichtigen, wie viele Daten wir berücksichtigen müssen; Die zweite besteht darin, zu wissen, wie groß der Bereich der Verteilung ist (dh der Unterschied zwischen der größten und der kleinsten Beobachtung)..
Nachdem die Klassen bereits definiert wurden, zählen wir, wie viele Daten in jeder Klasse vorhanden sind. Diese Zahl wird als Häufigkeit von Klassen bezeichnet und mit fi bezeichnet.
Wie wir zuvor gesagt hatten, haben wir, dass eine Häufigkeitsverteilung die Informationen verliert, die einzeln aus den einzelnen Daten oder Beobachtungen stammen. Aus diesem Grund wird ein Wert gesucht, der die gesamte Klasse darstellt, zu der er gehört. Dieser Wert ist die Klassenmarke.
Die Klassenmarke ist der Kernwert, den eine Klasse darstellt. Sie erhalten es, indem Sie die Grenzen des Intervalls addieren und diesen Wert durch zwei teilen. Wir könnten dies mathematisch wie folgt ausdrücken:
xich= (Untergrenze + Obergrenze) / 2.
In diesem Ausdruck xich bezeichnet die Marke der i-ten Klasse.
Geben Sie anhand des folgenden Datensatzes eine repräsentative Häufigkeitsverteilung an und erhalten Sie die Note der entsprechenden Klassen.

Da die Daten mit dem höchsten numerischen Wert 391 und dem niedrigsten 221 sind, liegt der Bereich zwischen 391 und 221 = 170.
Wir werden 5 Klassen auswählen, alle mit der gleichen Größe. Eine Möglichkeit, Klassen auszuwählen, ist wie folgt:

Beachten Sie, dass sich alle Daten in einer Klasse befinden. Diese sind disjunkt und haben denselben Wert. Eine andere Möglichkeit, die Klassen auszuwählen, besteht darin, die Daten als Teil einer kontinuierlichen Variablen zu betrachten, die einen beliebigen realen Wert erreichen kann. In diesem Fall können wir Klassen der Form betrachten:
205-245, 245-285, 285-325, 325-365, 365-405
Diese Art der Gruppierung von Daten kann jedoch zu einigen Mehrdeutigkeiten an den Grenzen führen. Zum Beispiel stellt sich im Fall von 245 die Frage: Zu welcher Klasse gehört sie, zur ersten oder zur zweiten?
Um diese Verwirrung zu vermeiden, wird eine Endpunktkonvention erstellt. Auf diese Weise ist die erste Klasse das Intervall (205.245], die zweite (245.285] und so weiter.

Sobald die Klassen definiert sind, berechnen wir die Häufigkeit und haben die folgende Tabelle:
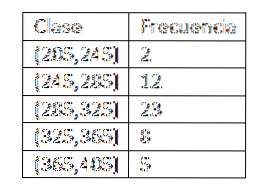
Nachdem wir die Häufigkeitsverteilung der Daten erhalten haben, suchen wir die Klassenmarkierungen für jedes Intervall. In der Tat müssen wir:
x1= (205+ 245) / 2 = 225
xzwei= (245+ 285) / 2 = 265
x3= (285+ 325) / 2 = 305
x4= (325+ 365) / 2 = 345
x5= (365+ 405) / 2 = 385
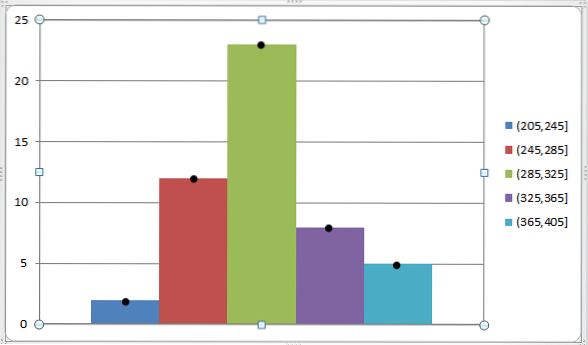
Wir können dies durch die folgende Grafik darstellen:
Wie bereits erwähnt, ist die Klassenmarkierung sehr funktional, um das arithmetische Mittel und die Varianz einer Gruppe von Daten zu ermitteln, die bereits in verschiedene Klassen gruppiert wurden..
Wir können das arithmetische Mittel als die Summe der Beobachtungen definieren, die zwischen der Stichprobengröße erhalten wurden. Aus physikalischer Sicht ist seine Interpretation wie der Gleichgewichtspunkt eines Datensatzes.
Das Identifizieren eines gesamten Datensatzes durch eine einzelne Nummer kann riskant sein, daher muss auch der Unterschied zwischen diesem Breakeven-Punkt und den tatsächlichen Daten berücksichtigt werden. Diese Werte werden als Abweichung vom arithmetischen Mittel bezeichnet, und mit diesen versuchen wir zu bestimmen, um wie viel das arithmetische Mittel der Daten variiert..
Der häufigste Weg, diesen Wert zu finden, ist die Varianz, die der Durchschnitt der Quadrate der Abweichungen vom arithmetischen Mittel ist.
Um das arithmetische Mittel und die Varianz eines in einer Klasse gruppierten Datensatzes zu berechnen, verwenden wir jeweils die folgenden Formeln:
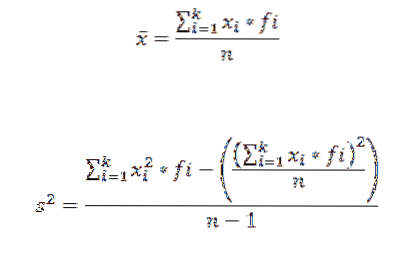
In diesen Ausdrücken xich ist die i-te Klassenmarke, fich stellt die entsprechende Häufigkeit dar und k die Anzahl der Klassen, in denen die Daten gruppiert wurden.
Unter Verwendung der im vorherigen Beispiel angegebenen Daten haben wir die Möglichkeit, die Daten der Häufigkeitsverteilungstabelle etwas weiter zu erweitern. Sie erhalten Folgendes:
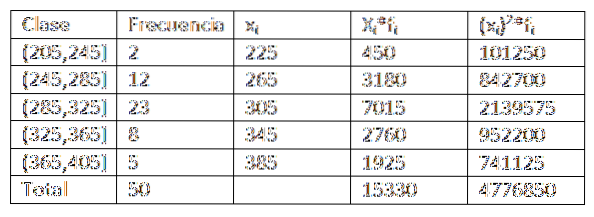
Durch Ersetzen der Daten in der Formel bleibt dann übrig, dass das arithmetische Mittel ist:
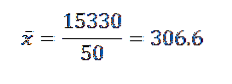
Seine Varianz und Standardabweichung sind:
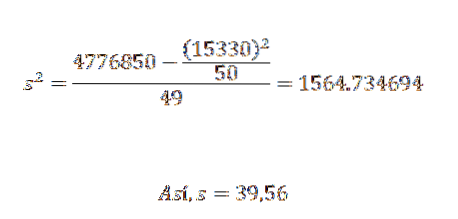
Daraus können wir schließen, dass die Originaldaten ein arithmetisches Mittel von 306,6 und eine Standardabweichung von 39,56 haben..



Bisher hat noch niemand einen Kommentar zu diesem Artikel abgegeben.